





大数据时代的到来,使得人们看到了从前所从未看到的世界关联性,预测到了所不曾预测到的事物:用Google的搜索词可以预测到战争、疾病的到来,用人们购物的数据可以遇到人们喜好、朋友、社交圈,用人们的社交圈可以预测到他们的消费偏好,这一切的实现,没有花费任何调查、设计、实验、推理,而仅仅是让沉没的数据再次发出声音。
那么在人力资源管理中,有哪些数据尚是没有充分利用的?这些数据又可以用做什么?又可以让我们看到哪些管理上的可能性呢?下面一一进行介绍。
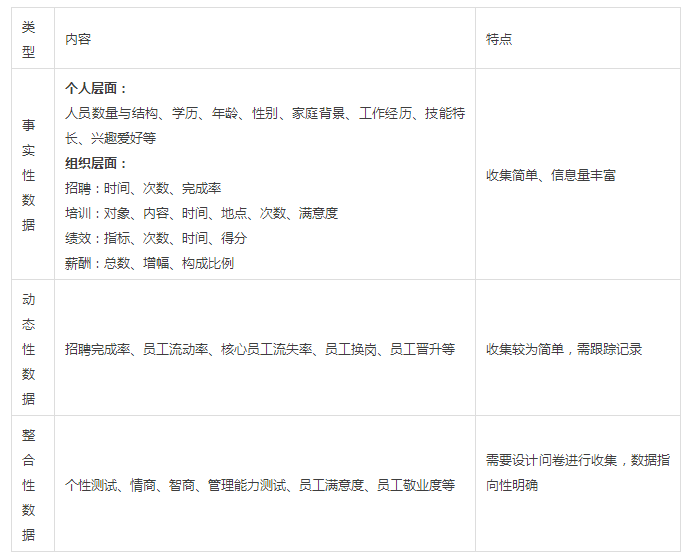
一、HR有哪些数据可用?
在日常的人力资源管理中,有哪些数据可以被利用呢?下面根据数据收集和使用的特点分为以下几种类型:
二、如何应用数据?
管理的最终目的是指向企业的长期发展和当前组织和个人绩效的提升,数据的利用的最终目的也应当是指向这两个方向。
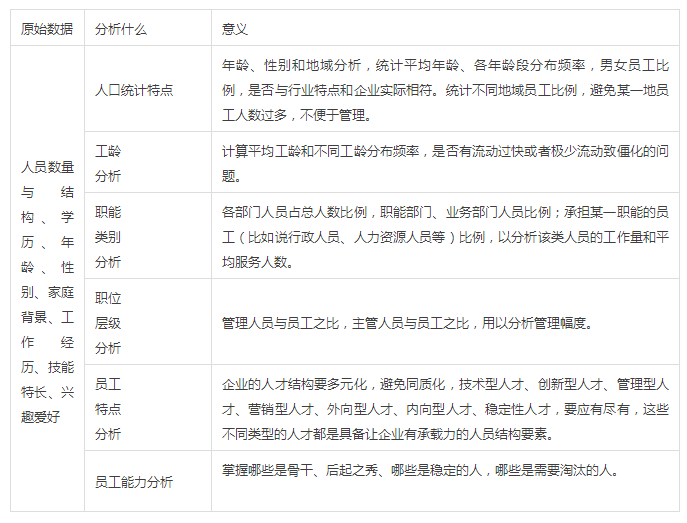
1、人员结构分析:
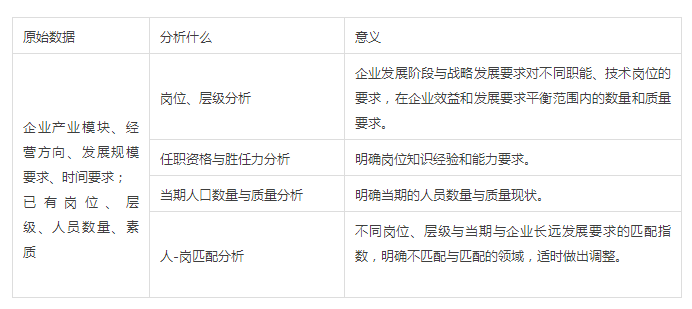
2、配置策略分析:
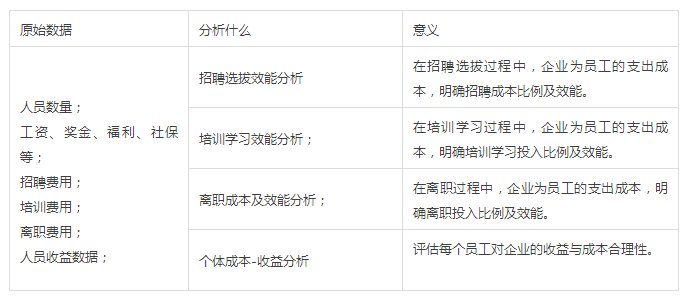
3、人员成本分析:
4、企业文化健康、活力分析:
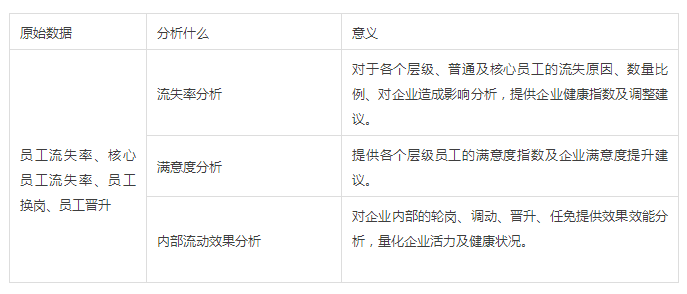
5、针对到岗位、个人的业绩驱动因素分析:
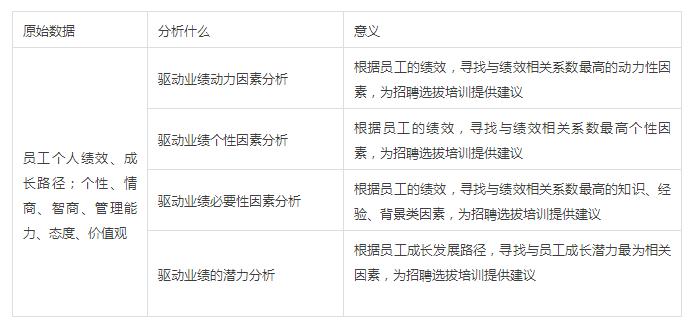
除此之外,有些数据本身需要通过进一步的统计处理,方能显示它的真正含义,下面举两个简单的例子进行说明。
三、测验数据常模转化
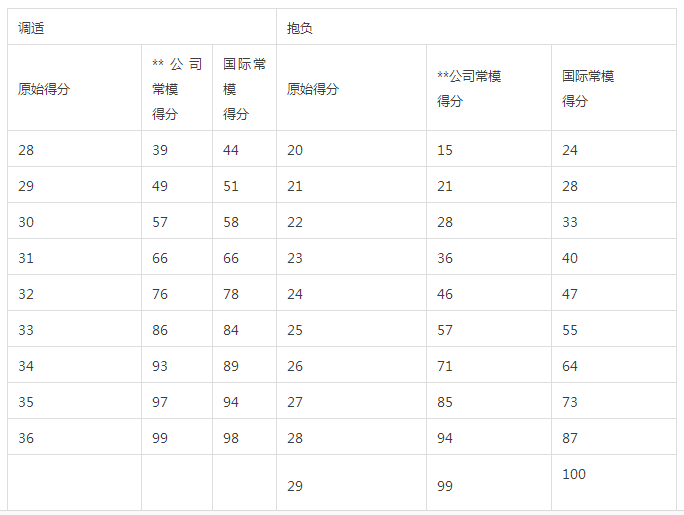
测验所得的原始数据,只能表明受测者的得分,却并不能表明该分数在人群中实际的水平如何,即使使用一些国际测验会提供转化后的分数,通常也是在全球的常模下的得分情况,如果企业想要知道受测者在本企业或者本行业的状况,则需要获取本企业或本行业的常模,方能得出比较准确的水平。下面是一个企业的心理测验成绩在全球常模和自己企业常模下的不同得分情况,可以看出,同一个分数,当与不同的常模做比较的时候,所得的分数是不同的,代表的水平也是不同的。
四、绩效数据跨单位跨部门比较
绩效分数部分是由人主观评价所得,这使得其分数本身就带有了主观性,有些分数实际上是不能直接使用的,需要进行进一步的加工处理,方能获取数据真正的意义。例如在绩效考核360评价的时候,评分者的尺度是存在差异的,有的人手松,有的人手紧,同一个人被不同人评价,也许得分会相差很大。但是,企业对于360数据的处理,通常是直接使用这些数据,有的时候会将这些不同人评价的分数权加之后进行排名,这样操作是非常不合理的,很容易引起争议。在实际处理中可以使用一些统计方法,例如标准分,来规避评分者评分尺度的差异,使得分数和排名真正反映出被评价者在评价者心目中的位置,这样也能解决跨单位跨部门之间的比较问题。
标准化每个评价者的分数,使用到相同的平均分和标准差,统一评价者的尺度;
被评价者甲的总分=上级权重*上级标准分+平级权重*平级标准分+下级权重*下级标准分。
五、数据的收集和管理
数据分析建立的基础是,数据可靠、全面、连续,在这个基础上建立起大数据分析或数据的整合才有可能产生有价值的结论。但同时HR管理模块众多,从战略规划到招聘、培训、绩效、薪酬、员工关系、企业文化等等,可能处处有问题,能进行分析的地方也很多。但资源有限,要使人力资源分析的作用发挥到最大,在数据的收集和管理上,有哪些事项是需要注意的呢?
从已有资源开始。HR部门手上有很多现成的数据,从这些数据入手,先一点点地做起来。数据本身是没有意义的,关键在于如何将数据与业绩关联起来。这确实需要创造性,并投入精力,基本的统计方法也是需要掌握的。
坚持下去。要有沉淀一旦决定要做分析工作,就要将它融入HR日常的业务工作中去,并安排专人负责日常数据的收集与整理。并且这个工作一定要有持久性,任何一个时间断面上的数据都难以单独进行有效的分析。组织内部历史数据的沉淀在评估和预测方面能发挥更大的作用。
打破常规,不断创新。大数据时代的崛起,在于没有拘泥于已有数据固有的意义,而是不断寻找关联性,利用这种关联性去预测整合。思维、技术、数据拉动数据分析的三辆马车,其中思维是启动机,一个好的利用数据的模式和思路,是使用数据进行创新管理的根本。
“工欲善其事,必先利其器”,作为一名人力资源从业者,需要利用本岗位所拥有的资源,那么这些曾经沉默的数据,就是进行精细化人力资源管理的好工具,并且这个工具一旦开始发挥作用,随着时间和数据的累积,就会越用越好用,会逐渐成为指导企业成长和发展的人才风向标。











